
до 50 узлов
в группе
до 110 подов
на каждую ноду кластера
До 112 CPU и 896 Gb RAM
на 1 ноду
99,95%
гарантированный уровень доступности
Функциональные возможности
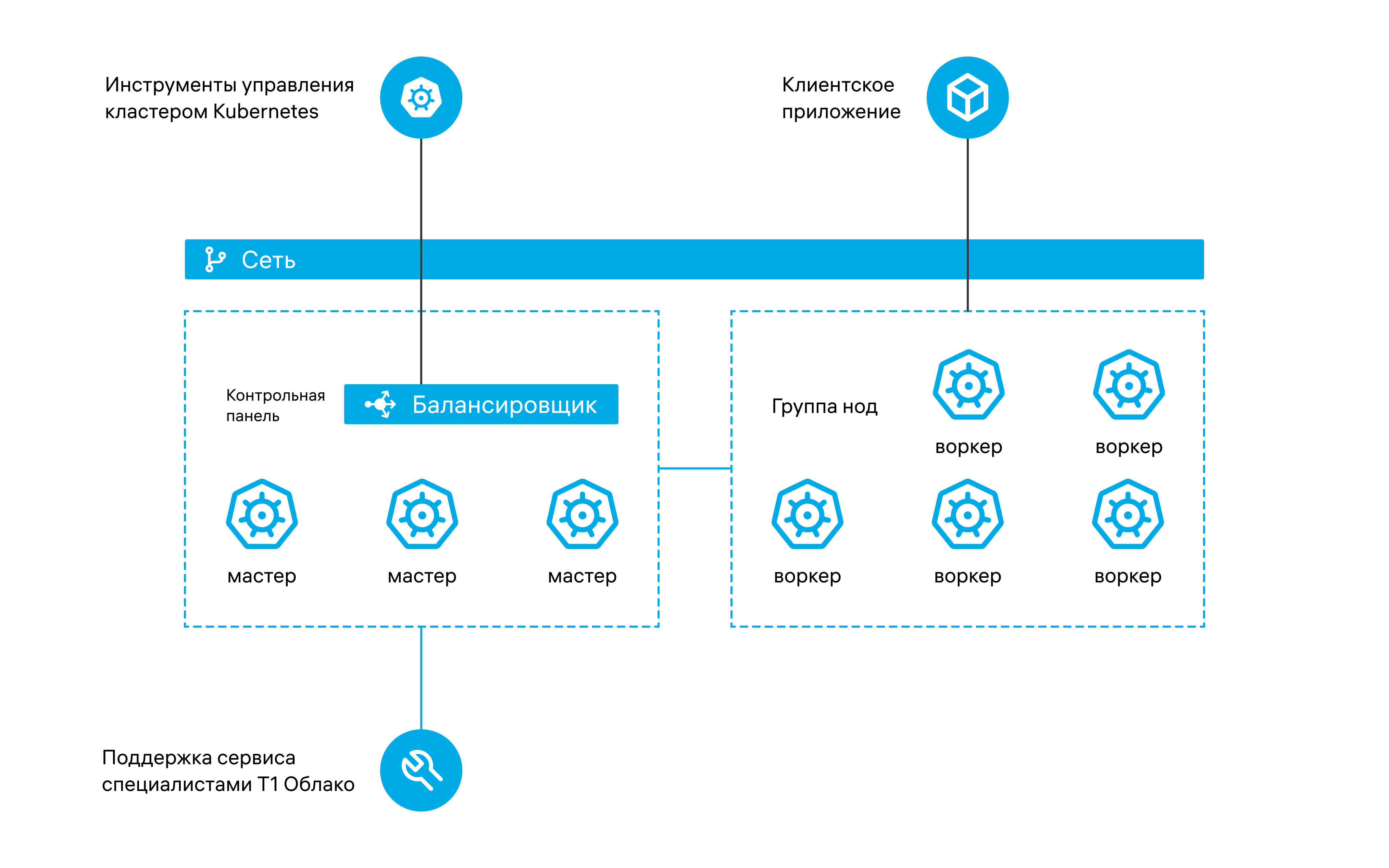
Надежная архитектура
Доступные конфигурации слоев управления
Зоны ответственности
Модель оплаты
Pay-As-You-Go
- Поминутная тарификация
- Оплата на основе фактического потребления только за вычислительные ресурсы и дисковое пространство в течение определенного времени
- В случае масштабирования ресурсов, учтем повышение или снижение уровня потребления
Документация
© Т1 Облако, 2021–2026
г. Москва, пр-кт Ленинградский, д. 36 стр. 41, помещ. 22.
Команда выделенной технической поддержки на связи 24/7
по телефону +7 (495) 727-09-81 и почте support@t1.cloud