
Если вы интересуетесь генеративным ИИ, то наверняка знаете, что LLM давно превратились из хайповой игрушки в рабочий инструмент для множества бизнес-задач: от создания небольших чат-ботов для клиентской поддержки до крупных мультимодальных моделей для генерации текстов, изображений и видео.
И хотя обучение и инференс моделей остаются основной причиной роста спроса на GPU, для участия в этой «вечеринке» не всегда нужен суперкар уровня H100 или H200. Речь о том, чтобы оптимально подобрать GPU под конкретный сценарий, будь то обучение скромного чат-бота на внутренних руководствах, проектирование или обработка терабайтов видео в 8K или создание корпоративной базы знаний для бигтеха. Под каждый сценарий — свой тип ускорителя, чтобы не ехать за хлебом на Феррари. Именно поэтому мы не стали ставить во все серверы исключительно флагманские видеокарты, а расширили линейку GPU различными моделями как для инференса, так и для гибридных сценариев.
Поделимся техническим обзором серверов с графическими ускорителями H200 и L40S, и их фотографиями прямо из ЦОДа. Расскажем не только о тензорных ядрах, Infiniband и видеопамяти, но и о том, как эти технологии помогают нашим клиентам развиваться.
⠀
Сравнение H200 с младшими братьями
H200, по сути, логическое продолжение модели H100, только усовершенствованное в некоторых аспектах. Обе модели построены на архитектуре NVIDIA Hopper и предназначены для генеративного ИИ и высокопроизводительных вычислений (HPC), включая обучение и инференс LLM.
Однако H200 превосходит предшественников по многим параметрам, начиная с объёма видеопамяти и пропускной способности и заканчивая ростом производительности в различных задачах. Подробные спецификации H200 вы найдёте на сайте Nvidia, а ниже кратко сравним основные характеристики H200 и других графических ускорителей марки Nvidia, которые представлены в Т1 Облако:
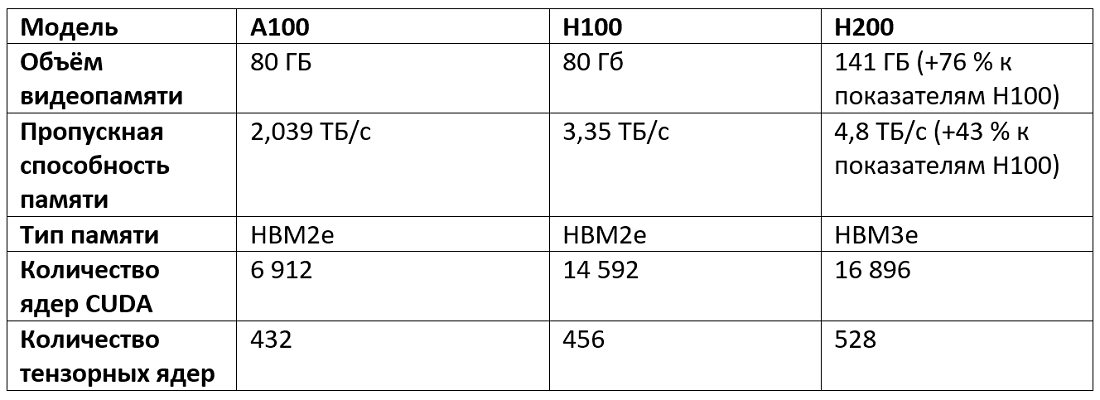
Если резюмировать, то основная особенность H200 — значительный рост пропускной способности и объёма памяти. Эти показатели критически важны для задач обучения и инференса.
Об L40S замолвите слово
Nvidia L40S отличается от других графических ускорителей своей универсальностью. Эта модель подходит как для обучения и инференса небольших и средних ИИ-моделей, так и для трёхмерного рендеринга, графических задач и обработки видео. Она уступает в мощности таким колоссам, как H100 и H200, но зато находится на одном уровне с топовыми потребительскими видеокартами и даже превосходит их по ряду характеристик.
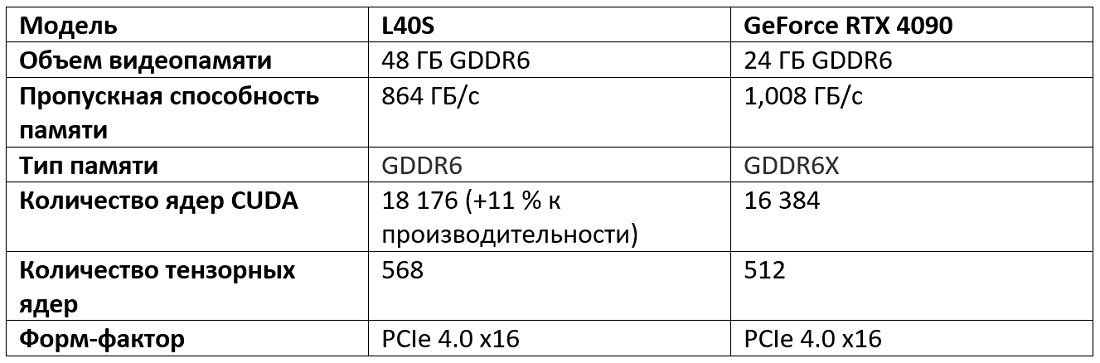
Ниже небольшое сравнение профессионального решения L40S и топовой десктопной видеокарты GeForce RTX 4090: обе построены на архитектуре Ada Lovelace:
Рассмотрим серверы поближе
К нам приехали вот такие красавчики: в каждом установлено по восемь NVIDIA H200, как на фото. Один такой крепыш весит около 107 кг:

Расчётное энергопотребление этого сервера — в районе 5,5-6,5 кВт. Такая прожорливость стала причиной, что в стойке на 7 кВт «живёт» только один сервер с H200:

Спецификация сервера с H200:
• два процессора Intel Xeon Platinum 8462Y+ 2,8 ГГц;
• 2 ТБ оперативной памяти DDR5 4800 МГц с поддержкой RDIMM;
• восемь Nvidia H200, каждая оснащена 141 ГБ памяти;
• интерфейс видеокарт — SMX;
• три сетевые карты Mellanox ConnectX-6 Lx 10/25GbE SFP28 2-Port;
• восемь сетевых карт Nvidia ConnectX-7 Single Port NDR для InfiniBand.
Фотообзор L40S
Сервер с L40S тоже рассчитан на восемь видеокарт. Инженерам ЦОДа с ним полегче, так как в нём всего 39 кг.

Потребляет наш герой около 3 кВт электроэнергии, и поэтому в одной стойке на 10 кВт дружно живут три сервера.
Спецификация сервера с L40S:
• два процессора AMD EPYC 9374F 32C 3,85 ГГц;
• 1,5 Тб оперативной памяти DDR5 4800 МГц;
• восемь Nvidia L40S, каждая оснащена 48 ГБ памяти;
• интерфейс видеокарты — PCIe Gen4.
«Скоростное шоссе» для передачи данных
Чтобы превращать отдельные графические ускорители в высокопроизводительные вычислительные среды, мы используем высокоскоростную сетевую технологию Infiniband. Она помогает объединить серверы с GPU H200 в одну скоростную сеть с пропускной способностью до 400 ГБ/с между виртуальными машинами. При этом практически отсутствует задержка в передаче данных. Это важно для эффективного обучения огромных LLM и других задач, когда даже миллисекунда задержки в сети может значительно повлиять на всю скорость обучения модели.
Кроме того, мы используем технологию GPUDirect RDMA, которая позволяет GPU напрямую обмениваться данными через сеть InfiniBand, минуя процессор и системную память. Таким образом, не только снижаются задержки, но и освобождается процессор для других задач, повышая общую эффективность системы.

Бирюзовые патч-корды — это Infiniband, а розовые — LAN-сеть
Процессор тоже на уровне
Как мы знаем, производительность вычислений зависит не только от параметров видеокарты, но и от характеристики центрального процессора. Архитектура каждого GPU сервера с H200 основана на двух мощных серверных процессорах пятого поколения Intel Xeon Platinum 8462Y+ с 2,8 ГГц и 2 ТБ оперативной памяти. Они помогают ускорять операции, часто встречающиеся в моделях глубокого обучения.
В каждом сервере с L40S стоят по два центральных процессора AMD EPYC 9374F 32C с 3,85 ГГц и 1,5 ТБ оперативной памяти.
Примеры использования
• Команда экспертов и технических специалистов Сайбокс, которые занимаются развитие LLM, использует наши ресурсы для обучения своих моделей. Подробнее об этом мы рассказывали в этой статье.
• Один из наших клиентов, Альфа-Банк, использует серверы с H200, чтобы тестировать и развивать технологии на основе генеративного искусственного интеллекта. Компания широко применяет ИИ-помощников, чтобы экономить время клиентов и упрощать работу сотрудников в разных подразделениях.
• Крупнейшая сеть детских товаров с помощью вычислительных мощностей GPU Т1 Облако обучает крупные ML-модели и на их основе развивает программы лояльности для клиентов и создаёт персонализированные промокоды.
О других примерах и сценариях использования GPU читайте в другой нашей статье.
Напомним, что видеокарты NVIDIA H200, L40S и другие модели доступны в облаке по модели GPU as a Service. Это означает, что можно сразу пользоваться сервисом, обучать ИИ-модели и проверять гипотезы, создавать трёхмерные визуализации и реализовывать сложные и интересные проекты. После выполнения всех вычислений виртуальные GPU можно отключить, оплатив только период фактического использования карт.
Если хотите больше узнать о H200, L40S, возможностях Infiniband и других особенностях инфраструктурных технологий в облаке, с удовольствием обсудим с вами эти темы — пишите нам. А еще дадим протестировать наши графические ускорители, чтобы вы были уверены в их надежности и производительности.
Начните тестирование наших сервисов уже сегодня



© Т1 Облако, 2021–2026
г. Москва, пр-кт Ленинградский, д. 36 стр. 41, помещ. 22.
Команда выделенной технической поддержки на связи 24/7
по телефону +7 (495) 727-09-81 и почте support@t1.cloud