Создание кластера PostgreSQL
О геораспределённости
Для геораспределённости необходимо создать кластеры в разных зонах доступности. Например, один кластер в зоне доступности ru-central1 и второй — в ru-central2.
Обратите внимание: один кластер работает только в пределах одной зоны доступности. Межзональных («растянутых») кластеров не существует. Поэтому для построения геораспределённого решения необходимо создать несколько кластеров в разных зонах и обеспечить распределение приложения между ними.
Если все экземпляры сервиса размещены только в одном кластере или в нескольких кластерах, но внутри одной зоны, архитектура не будет геораспределённой. В таком случае при сбое на уровне зоны возможен простой сервиса.
Чтобы создать кластер:
- Выберите проект, в котором нужно заказать Managed Service for PostgreSQL.
- В главном меню портала перейдите в раздел Ресурсы → Базы данных → Managed Service for PostgreSQL.
- Нажмите на кнопку Подключить или на кнопку
 Создать кластер, если в проекте уже есть созданный кластер.
Создать кластер, если в проекте уже есть созданный кластер. - Заполните поля:

Базовые параметры:Название кластера * — уникальное имя нового кластера в рамках проекта. Введите название или нажмите Сгенерировать название, чтобы сформировать название кластера вида postgresql-<порядковый номер>, например, postgresql-0001. Последующим кластерам будут присваиваться названия с увеличивающимся порядковым номером;
Описание кластера — заполняется при необходимости;
Версия Postgresql * — доступная версия PostgreSQL.
Нажмите на кнопку Вперед. Заполните поля:
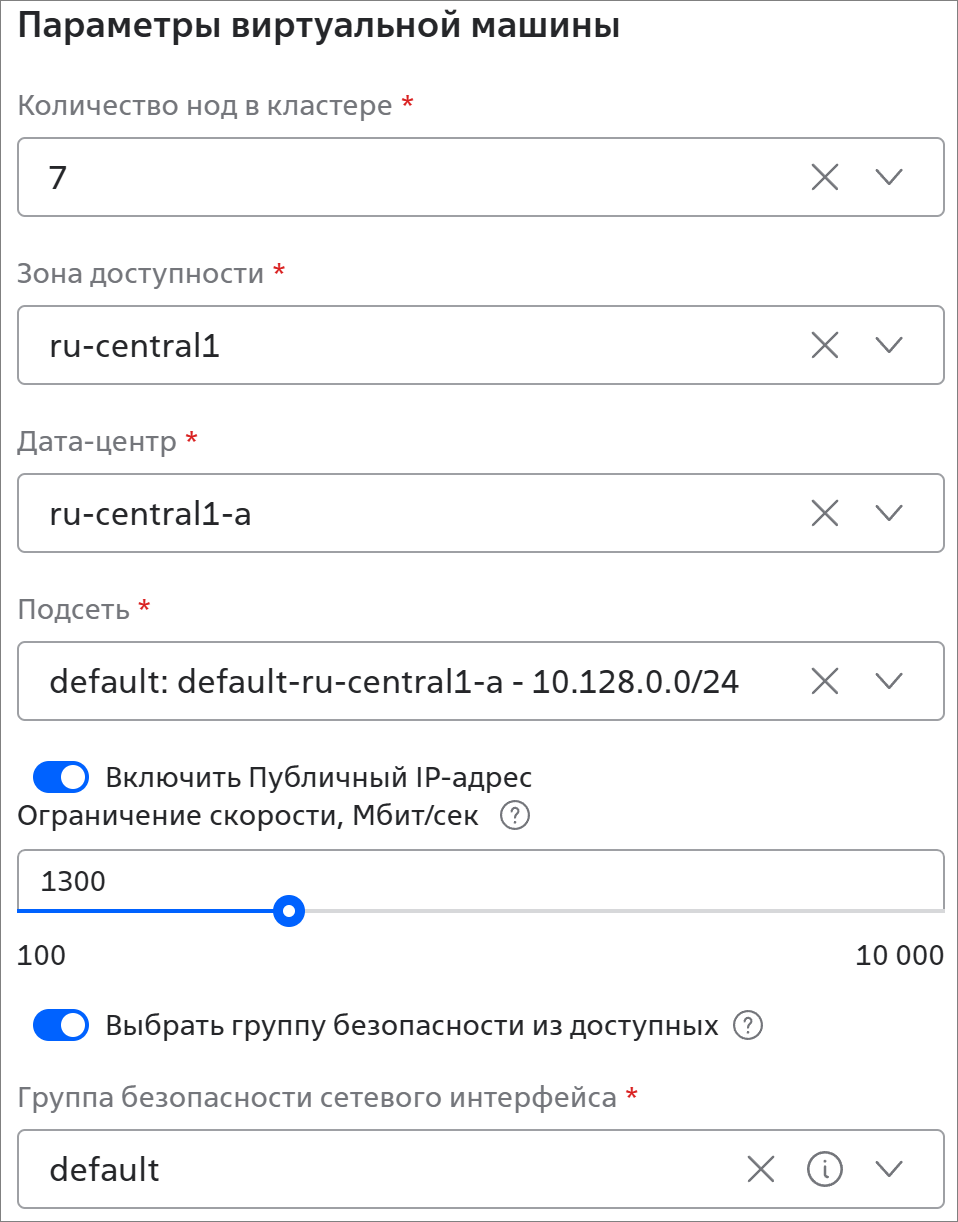 Параметры виртуальной машины:
Параметры виртуальной машины:- Количество нод в кластере * — 1, 3, 5 или 7;
- Зона доступности * и Дата-центр * — зона доступности и ЦОД, в котором будет находиться кластер;
- Подсеть * — подсеть, к которой будет подключен кластер;
- Включить Публичный IP-адрес — активируйте переключатель, если к кластеру нужен доступ из сети Интернет. Если в кластере 1 нода, то публичный IP-адрес будет привязан к ней. Если в кластере более 1 ноды, то публичный IP-адрес будет привязан к виртуальному IP-адресу кластера;
- Ограничение скорости, Мбит/сек — ограничение скорости интернет-трафика на подключаемом IP-адресе. Значение должно быть кратно 100;
- Выбрать группу безопасности из доступных — активируйте переключатель и выберите Группу безопасности сетевого интерфейса *. Если нужной группы безопасности нет, создайте её. Если переключатель не активирован, группа безопасности sg_<имя кластера> создаётся автоматически;
Важно
Если имя автоматически создаваемой группы безопасности не уникально в рамках проекта, удалите существующую группу безопасности с именем sg_<имя кластера> или переименуйте создаваемый кластер.
Группа безопасности сетевого интерфейса * — правила для управления сетевым интерфейсом кластера.
Важно
Чтобы подключиться к кластеру, у группы безопасности должно быть правило, разрешающее входящий трафик по определённому порту для протокола TCP. Подробнее см. раздел Доступ к кластеру PostgreSQL.

Вычислительные ресурсы:- Тип:
- Публичные — для публичного облака;
- Персональные — для частного облака;
- Семейство — семейство процессоров:
- General-purpose — используется переподписка 1 к 3, т.е. на одно физическое ядро, с учётом Hyper-Threading, приходится 3 виртуальных ядра.
Серии процессоров:- Intel Cascade Lake 2.2 GHz — для экономных проектов с умеренной нагрузкой. Например, для тестовых сред, маломощных веб-сервисов и приложений;
- Intel Cascade Lake 3.0 GHz — для задач, требующих высокой тактовой частоты vCPU. Например, для высоконагруженных веб-приложений (Python, Java), транзакционных нагрузок (1С, ERP-системы);
- Intel Ice lake 2.8 GHz — для сбалансированной производительности. Например, для средненагруженных баз данных, микросервисов и контейнерных приложений;
- Advanced — используется переподписка 1 к 1, т.е. на одно физическое ядро приходится одно виртуальное.
Серии процессоров:- Intel Cascade Lake 3.0 GHz — для задач, требующих высокой тактовой частоты vCPU. Например, для высоконагруженных веб-приложений (Python, Java), транзакционных нагрузок (1С, ERP-системы);
- Intel Ice lake 2.8 GHz — для сбалансированной производительности. Например, для средненагруженных баз данных, микросервисов и контейнерных приложений.
Примечание
В зонах доступности ru-central2 и ru-central3 доступен только процессор Intel Ice lake 2.8 GHz.
- General-purpose — используется переподписка 1 к 3, т.е. на одно физическое ядро, с учётом Hyper-Threading, приходится 3 виртуальных ядра.
- vCPU, шт. — количество процессоров;
- RAM, ГБ — объём оперативной памяти;
- Выбрана конфигурация — конфигурация сервера определяется автоматически на основании выбранного количества процессоров (vCPU) и объёма оперативной памяти (RAM). Подробнее см. раздел Конфигурации сервера.

Объём хранилища:
Размер диска, ГБ * — размер выделенной памяти на каждой ноде кластера, от 25 ГБ до 2048 ГБ;
- Тип * — тип диска:
- High cluster 4 - IOPS Read: 15000 IOPS Write: 5000;
- High cluster 5 - IOPS Read: 15000 IOPS Write: 5000;
- High cluster 6 - IOPS Read: 15000 IOPS Write: 5000;
- Average cluster 2 - IOPS Read: 10000 IOPS Write: 3000;
- Average cluster 4 - IOPS Read: 10000 IOPS Write: 3000.
IOPS — операции чтения и записи. Чем больше проводится операций чтения, тем меньше операций записи, и наоборот. При выполнении операций расходуется один и тот же дисковый ресурс.
Примечание
В зонах доступности ru-central2 и ru-central3 доступен только тип диска Average IOPS Read: 10000 IOPS Write: 3000.
Типы дисков отличаются производительностью и количеством IOPS. Подробнее см. раздел Задержка и производительность дисков.
- Нажмите на кнопку Вперед. Заполните поля:

Параметры базы данных:
- Создать кластер из резервной копии — активируйте переключатель, чтобы создать кластер из резервной копии;
- Выберите кластер с нужной резервной копией * — название кластера, который нужно восстановить;
- Выберите резервную копию * — название резервной копии можно посмотреть на вкладке Резервные копии кластера, который нужно восстановить.

Настройки СУБД:
Примечание
Вы можете:
- изменить значение параметра, заданного по умолчанию;
указать значение для незаданного параметра. Для этого удалите // перед параметром и присвойте ему значение. Например, чтобы указать объём памяти для кеширования данных, удалите // перед параметром effective_cache_size и присвойте ему значение:
- указать дополнительные параметры, с которыми можно ознакомиться в официальной документации PostgreSQL.
- Настроить СУБД — активируйте переключатель, если необходимо изменить параметры СУБД, установленные по умолчанию:
work_mem — объём памяти в килобайтах, который может быть использован для операций сортировки и хеширования в рамках одного запроса;
autovacuum — автоматический процесс в PostgreSQL, который выполняет задачи очистки и анализа таблиц (
VACUUMиANALYZE) для поддержания производительности базы данных;seq_page_cost — приблизительная стоимость чтения одной страницы с диска, которое выполняется в серии последовательных чтений;
shared_buffers — объём памяти, выделяемой для кеширования данных PostgreSQL. Указывается в блоках по 8 КБ, количество блоков должно быть не менее 16 (128 КБ). Например, если указать значение 262144, то shared_buffers будет 2 ГБ;
max_connections — максимальное число одновременных подключений к серверу БД, не менее 10;
max_wal_senders — максимально допустимое число одновременных подключений ведомых серверов или клиентов потокового копирования, от 10 до 100;
random_page_cost — приблизительная стоимость чтения одной произвольной страницы с диска;
autovacuum_naptime — интервал времени в секундах между циклами работы autovacuum-демона. Определяет, как часто PostgreSQL будет проверять таблицы на необходимость выполнения операций VACUUM и ANALYZE;
effective_cache_size — объём памяти, который PostgreSQL предполагает доступным для кеширования данных операционной системой. Указывается в блоках по 8 КБ;
maintenance_work_mem — объём памяти в килобайтах, который может быть использован для операций обслуживания, таких как VACUUM, CREATE INDEX, ALTER TABLE и т.д. Параметр влияет на скорость выполнения этих операций;
max_replication_slots — максимальное число слотов репликации, которое сможет поддерживать сервер, от 10 до 100;
effective_io_concurrency — количество операций ввода-вывода, которые PostgreSQL может выполнять параллельно;
default_statistics_target — количество выборок, используемых для сбора статистики о данных в таблицах;
max_locks_per_transaction — среднее число блокировок объектов, выделяемое для каждой транзакции, от 10 до 4096;
Примечание
Отдельные транзакции могут заблокировать и больше объектов, если все они умещаются в таблице блокировок.
max_prepared_transactions — максимальное число транзакций, которые могут одновременно находиться в подготовленном состоянии, от 0 до 1000. При нулевом значении механизм подготовленных транзакций отключается;
autovacuum_vacuum_cost_delay — задержка в миллисекундах между циклами выполнения операций VACUUM, выполняемых autovacuum-демоном;
checkpoint_completion_target — целевое время для завершения процедуры контрольной точки, как коэффициент для общего времени между контрольными точками, от 0 до 1.
Важно
При указании некорректных значений кластер может не развернуться.
7. Нажмите на кнопку Вперед. Заполните поля:

Дополнительные параметры:
- Автоматическое резервное копирование — активируйте переключатель, если требуется автоматическое резервное копирование всех баз данных кластера, и заполните поля:
- Ежедневно или Каждый час — периодичность создания резервных копий;
- Количество хранимых резервных копий * — от 1 до 7. При достижении указанного количества новая копия заменяет самую старую;
- Время резервного копирования UTC:
- при выборе Ежедневно — время в формате hh:mm. Значение по умолчанию 00:00;
- при выборе Каждый час — количество минут от 0 до 59. Например, если указать 30, то резервная копия будет создаваться в 00:30, 01:30, 02:30 и т.д.
В указанное время с ноды в кластере Standalone или с ноды-лидера в кластере Patroni создаётся полная копия всех баз данных. Копия отображается на вкладке Резервные копии;
- День окна обслуживания * и Время обслуживания * — день недели и интервал времени (в вашем часовом поясе), когда специалисты Т1 Облако могут выполнять технические работы.
Настройки подключения:
Разрешить только TLS подключения — активируйте переключатель, если требуется подключаться к кластеру только по TLS .
Если переключатель не активирован, то можно подключаться и по TLS, и по non-TLS. Подробнее о шифровании данных см. в разделе Шифрование данных с pgcrypto.
Настройки шифрования:
- scram-sha-256 — обеспечивает высокую стойкость к перехвату и атакам благодаря солированию, хешированию SHA-256 и взаимной проверке пароля. Этот метод рекомендуется использовать во всех современных СУБД PostgreSQL для надёжной аутентификации клиентских приложений;
md5 — преимуществом является более высокая скорость вычисления хеша пароля и совместимость со старыми клиентами, не поддерживающими SCRAM . md5 стоит применять только в устаревших окружениях, где обновление до scram-sha-256 невозможно.
8. Нажмите на кнопку Заказать. Кластер Standalone разворачивается около 5 минут, кластер Patroni — около 10 минут.
Созданный кластер отображается на портале со статусом В порядке — ![]() :
:

Чтобы посмотреть информацию о кластере, нажмите на строку с нужным кластером. Откроется страница с информацией о кластере:

- на вкладке Информация отображаются основные параметры кластера;
- на вкладке Пользователи отображаются пользователи, которым назначена роль в кластере и предоставлен доступ к базам данных;
- на вкладке Базы данных отображаются созданные базы данных;
- на вкладке Ноды отображается список нод в кластере, их роли, внутренние и публичные IP-адреса;
- на вкладке Резервные копии отображаются созданные резервные копии и их параметры;
- на вкладке Настройки СУБД отображаются текущие параметры СУБД, которые можно изменить;
- на вкладке История действий указаны действия пользователя с кластером.
Чтобы обновить информацию о кластере, нажмите на кнопку ![]() .
.
В созданном кластере можно добавить или удалить ноду, изменить CPU/RAM, увеличить размер диска, подключить или отключить публичный IP-адрес, удалить кластер. Подробнее см. раздел Действия с кластером PostgreSQL.