Создание кластера Kafka
Чтобы создать кластер:
- Выберите проект, в котором нужно заказать Managed Service for Kafka.
- В главном меню портала перейдите в раздел Ресурсы → Приложения → Managed Service for Kafka → Кластеры.
- Нажмите на кнопку Создать кластер или на кнопку
 Заказать, если в проекте уже есть созданный кластер.
Заказать, если в проекте уже есть созданный кластер. - Заполните поля:

- Метка * — тег, который присваивается каждому кластеру и помогает ориентироваться в созданных кластерах. Длина метки — от 3 до 256 символов;
Имя кластера * — уникальное имя кластера в рамках проекта. Значение по умолчанию — kafka-<номер>, например, kafka-0001. Последующим кластерам будут присваиваться названия с увеличивающимся порядковым номером;
- Описание — описание кластера, заполняется при необходимости;
- Количество брокеров Kafka * — количество серверов Kafka от 1 до 20. При заказе 1 брокера Kafka и ZooKeeper разворачиваются на одном сервере. При заказе больше 1 брокера Kafka автоматически заказывается 3 хоста ZooKeeper.
Примечание
Хост ZooKeeper создаётся с конфигурацией:
- vCPU — 2 шт.;
- RAM — 4 ГБ;
- объём диска — 35 ГБ.
- Версия Apache Kafka *;
- Время хранения информации в топиках, мин — время хранения данных в любом топике в памяти до их сброса на диск, от 30 до 20160 минут;
- Зона доступности * и Дата-центр * — зона доступности и ЦОД, в которых будет находиться кластер.

Вычислительные ресурсы:
Семейство — семейство процессоров:
- General-purpose — используется переподписка 1 к 3, т.е. на одно физическое ядро, с учётом Hyper-Threading, приходится 3 виртуальных ядра.
Серии процессоров:- b2 Intel Cascade Lake 2.2 GHz — для экономных проектов с умеренной нагрузкой. Например, для серверов общего назначения, тестовых сред, маломощных веб-сервисов и приложений;
- b3 Intel Cascade Lake 3.0 GHz — для задач, требующих высокой тактовой частоты vCPU. Например, для высоконагруженных веб-приложений (Python, Java), транзакционных нагрузок (1С, ERP-системы);
- b5 Intel Ice lake 2.8 GHz — для сбалансированной производительности. Например, для средненагруженных баз данных, микросервисов и контейнерных приложений, виртуализированных сред (Kubernetes);
- Advanced — используется переподписка 1 к 1, т.е. на одно физическое ядро приходится одно виртуальное.
Серии процессоров:- a1 Intel Cascade Lake 3.0 GHz — для задач, требующих высокой тактовой частоты vCPU. Например, для высоконагруженных веб-приложений (Python, Java), транзакционных нагрузок (1С, ERP-системы);
- a5 Intel Ice lake 2.8 GHz — для сбалансированной производительности. Например, для средненагруженных баз данных, микросервисов и контейнерных приложений, виртуализированных сред (Kubernetes);
- GPU — подходит для самых требовательных задач: искусственный интеллект (обучение и инференс моделей), высокопроизводительные вычисления (HPC), симуляции, научные исследования, инженерные расчёты, аналитика в реальном времени и т.п.
Для 1 сервера можно заказать 1, 2, 4 или 8 GPU. Для заказа GPU обратитесь к sales-менеджеру.
vCPU, шт. — количество процессоров.
RAM, ГБ — объём оперативной памяти.
Выбрана конфигурация — конфигурация сервера определяется автоматически на основании выбранного количества процессоров (vCPU) и объёма оперативной памяти (RAM). Подробнее см. раздел Конфигурации сервера.
Примечание
В дата-центрах ru-central2-a и ru-central3-a пока доступны:
- семейство General-purpose (только серия b5 Intel Ice lake 2.8 GHz);
- семейство GPU.

Дополнительный диск — диск, на который устанавливается сервис Kafka:
Размер диска, ГБ * — объём дополнительного диска в ГБ, от 10 до 2048 ГБ;
- Тип * — тип диска:
- High cluster 4 - IOPS Read: 15000 IOPS Write: 5000;
- High cluster 5 - IOPS Read: 15000 IOPS Write: 5000;
- High cluster 6 - IOPS Read: 15000 IOPS Write: 5000
- Average cluster 2 - IOPS Read: 10000 IOPS Write: 3000;
- Average cluster 4 - IOPS Read: 10000 IOPS Write: 3000;
- Basic - IOPS Read: 3000 IOPS Write: 1000;
- Light - IOPS Read: 500 IOPS Write: 300.
IOPS — операции чтения и записи. Чем больше проводится операций чтения, тем меньше операций записи, и наоборот. При выполнении операций расходуется один и тот же дисковый ресурс.
Примечания
- Тип дисков Average cluster и High cluster рекомендуется использовать для серверов, предназначенных для построения кластера на независимых друг от друга дисках. Например, при организации систем типа Primary-Secondary (Master-Slave).
- Для оптимальной работы и надёжности хранения данных диски Light и Basic проходят ежедневную проверку и исправление ошибок. В процессе этих проверок могут увеличиваться задержки (latency). Если вам нужна стабильно высокая производительность дисков, выбирайте High cluster. Подробнее см. раздел Задержка и производительность дисков.
- В дата-центрах ru-central2-a и ru-central3-a доступны только типы дисков Average и High.
- Удалять вместе с сервером — установите флажок, чтобы при удалении кластера диск автоматически удалился;

- Подсеть * — подсеть, к которой будет подключен кластер;
Включить Публичный IP-адрес — активируйте переключатель, если к кластеру нужен доступ из сети Интернет. К каждому брокеру в кластере будет привязан публичный IP-адрес, который отображается на вкладке Общая информация в столбце External socket;
- Ограничение скорости, Мбит/сек — ограничение скорости интернет-трафика на подключаемом IP-адресе. Значение должно быть кратно 100;
- Выбрать существующую группу безопасности — активируйте переключатель, чтобы выбрать существующую группу безопасности и не создавать новую;
- Группы безопасности сетевого интерфейса * — правила, контролирующие входящий и исходящий трафик сервера.
Важно
При первом заказе кластера не активируйте переключатель Выбрать существующую группу безопасности. Группа безопасности с нужными правилами создаётся автоматически после заказа кластера. Подробнее см. раздел Группы безопасности для кластера Kafka.

Методы аутентификации — способы проверки и подтверждения прав пользователя для подключения к кластеру Kafka:
NONE — отсутствие аутентификации. Все пользователи имеют полный доступ к брокерам Kafka без каких-либо проверок;
Важно
В целях безопасности не рекомендуем выбирать данный метод.
SASL/PLAIN — аутентификация по логину и паролю:
Имя пользователя * — логин пользователя для подключения к кластеру Kafka.
Пароль * — пароль пользователя для подключения к кластеру Kafka.
Чтобы отобразить пароль, нажмите на кнопку
 .
.
Чтобы скопировать пароль, нажмите на кнопку .
.
Чтобы сгенерировать пароль, нажмите на кнопку ;
;
- TLS — аутентификация с использованием пользовательского или неквалифицированного сертификата.
Если пользовательский или неквалифицированный сертификат уже создан в сервисе Certificate & Secret Manager, активируйте переключатель Выбрать существующий сертификат и Выберите тип сертификата *:- Импортированный — выберите импортированный пользовательский сертификат;
- Сгенерированный — выберите неквалифицированный сертификат с типом user.
Если неквалифицированный сертификат не создан в сервисе Certificate & Secret Manager, создайте его:
- Деактивируйте переключатель Выбрать существующий сертификат.
- Заполните поля:
Введите cn сертификата * — сommon name (CN) сертификата. Имя субъекта, для которого выпущен сертификат. Например, доменное имя или имя пользователя/устройства. Используется для идентификации владельца сертификата;
Введите название сертификата * — название сертификата.
Ознакомьтесь с примечанием и установите флажок Я прочитал информацию выше.
Примечание
В результате после заказа кластера сгенерируется неквалифицированный сертификат. Скачайте сертификат и приватный ключ для подключения к кластеру Kafka.
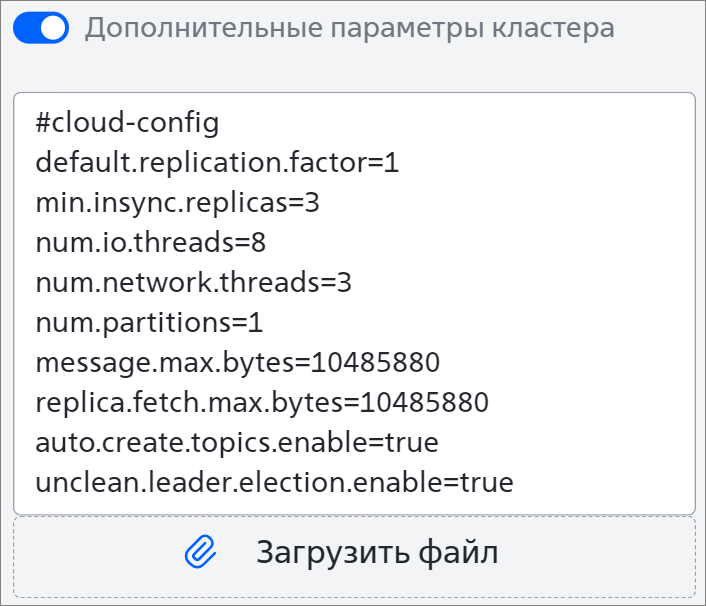
Если нужно задать дополнительные параметры кластера, активируйте переключатель Дополнительные параметры кластера. После первой строки #cloud-config напишите параметры со значениями или загрузите текстовый файл. Например:
5. После заполнения полей отобразится стоимость заказа. Нажмите на кнопку Заказать. Кластер разворачивается около 10 минут.
Созданный кластер отобразится на портале:

Чтобы посмотреть подробную информацию о кластере, выберите нужный кластер. Откроется страница с информацией о кластере:

- на вкладке Общая информация отображаются основные параметры кластера, в том числе IP-адреса для подключения к Kafka;
- на вкладке Сертификаты содержится информация о сертификате для подключения к Kafka с отображением дат начала и окончания действия сертификата. Подробнее см. раздел Сертификаты кластера Kafka;
- на вкладке Топики отображаются созданные топики;
- на вкладке История действий указаны действия пользователя с кластером.
У кластера можно изменить вычислительные ресурсы, включить/выключить его, изменить параметры, подключить/отключить публичный IP-адрес, изменить ограничение скорости интернет-трафика, расширить дополнительный диск, изменить метод аутентификации, увеличить количество брокеров и т.д. Подробнее см. раздел Действия с кластером Kafka.